Introduction
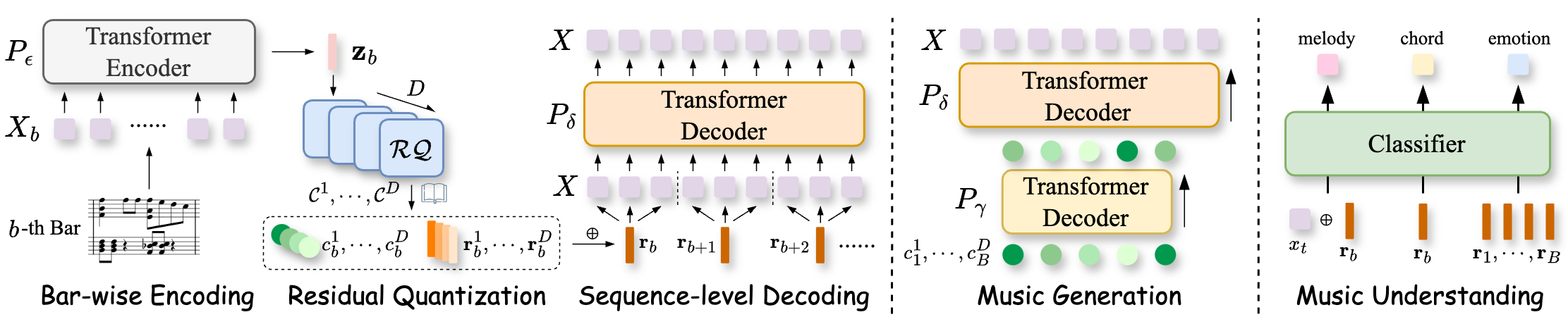
In this paper, we propose MuseTok, a tokenization method for symbolic music, and investigate its effectiveness in both music generation and understanding tasks. MuseTok employs RQ-VAE on bar-wise music segments within a transformer-based encoder-decoder framework, producing music codes that achieve high-fidelity music reconstruction and accurate understanding of music theory. We further applied learned MuseTok to music generation and semantic understanding tasks, to comprehensively evaluate the quality of such representations.
We provide audio demonstrations and additional experimental details to supplement experiment sections of the paper, organized as follows:
- Dataset Statistics & Examples (for Section 4.1)
- Music Reconstruction (for Section 4.2)
- Music Continuation (for Section 4.3)
- How MuseTok Learns Music (for Section 4.5)
Dataset Statistics & Examples
We utilize public-domain music data for model training, with representative samples provided below to show the characteristics of our datasets. The #bars are averaged over a dataset, while #events are averaged per bar.
| Dataset | # pieces | # bars | # events | Genres | Sample1 | Sample2 |
|---|---|---|---|---|---|---|
| PDMX-monophonic [1] | 163,366 | 27.36 | 19.33 | mixed | ||
| PDMX-chorale [1] | 25,597 | 35.24 | 44.77 | mixed | ||
| POP909 [2] | 886 | 83.52 | 62.31 | pop | ||
| EMOPIA [3] | 1,071 | 17.79 | 46.73 | pop | ||
| Pop1k7 [4] | 1,747 | 104.59 | 39.39 | pop | ||
| Hymnal [5] | 1,606 | 18.47 | 47.05 | folk | ||
| Multipianomide [6] | 457 | 95.64 | 47.89 | classical | ||
| Ragtime [7] | 457 | 139.16 | 49.32 | jazz | ||
| Summary | 195,187 | 29.21 | 24.30 | - | - | - |
Reference:
[1] P. Long, Z. Novack, T. Berg-Kirkpatrick, and J. J. McAuley, “PDMX: A large-scale public domain musicxml dataset for symbolic music processing,” in Proc. ICASSP, 2025.
[2] Z. Wang, K. Chen, J. Jiang, Y. Zhang, M. Xu, S. Dai, and G. Xia, “POP909: A pop-song dataset for music arrangement generation,” in Proc. ISMIR, 2020.
[3] H. Hung, J. Ching, S. Doh, N. Kim, J. Nam, and Y.-H. Yang, “EMOPIA: A multi-modal pop piano dataset for emotion recognition and emotion-based music generation,” in Proc. ISMIR, 2021.
[4] W. Hsiao, J. Liu, Y. Yeh, and Y.-H. Yang, “Compound Word Transformer: Learning to compose full song music over dynamic directed hypergraphs,” in Proc. AAAI, 2021.
[5] https://www.hymnal.net/en/home
[7] https://www.ragsrag.com/pr/pr.html
Music Reconstruction
We present samples below to demonstrate the performance of three models (VAE, MuseTok-Small and MuseTok-Large) to reconstruct the Original pieces. Here, d denotes the hidden dimension, D the quantization depth, and K the codebook size.
- VAE (d = 128)
- MuseTok-Small (D = 8, K = 1024, d = 128)
- MuseTok-Large (D = 16, K = 2048, d = 128)
| Original | VAE | MuseTok-Small | MuseTok-Large |
|---|---|---|---|
Music Continuation
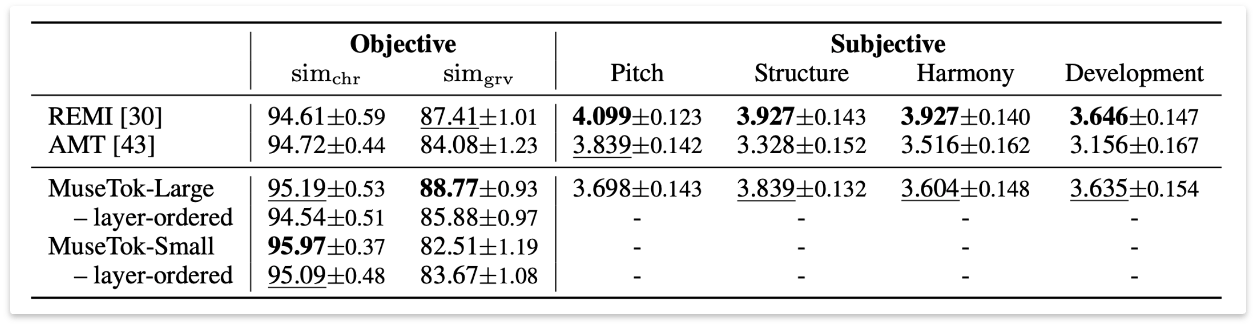
To assess the performance of our model (MuseTok-Large) and two baselines (REMI and AMT) on the music continuation task, we conduct online listening tests to collect human assessment on the generation quality. (Please refer to the paper for more details about objective evaluation.)
After listening to the primer, participants are responsible to rate the generated continuations in a 5-point Likert scale for the following questions:
- Pitch: Are there any notes that sound out of key (0 score), or align with each other (5 score)regardless of the primer?
- Structure: How well does the generated part follow the rhythm and structure of the primer?
- Harmony: How well does the generated part align with the chord progression of the primer?
- Development: How coherent and engaging is the musical flow and motif development following the primer?
A total of 24 responses are collected, with each response containing 8 groups of generated samples randomly selected from 32 primers in the test set, resulting in 192 ratings per model for each aspect.
The generation performance on objective and subjective metrics is presented below:
Below are some example music primers and their corresponding continuations that were presented to participants during the listening test:
| Primer | MuseTok | REMI | AMT |
|---|---|---|---|
When handling long-context primers, MuseTok demonstrates greater robustness compared to REMI-like generation frameworks:
| Primer | MuseTok | REMI | AMT |
|---|---|---|---|
We also present generation samples from MuseTok without primers here to show its effectiveness on content generation:
How MuseTok Learns Music?
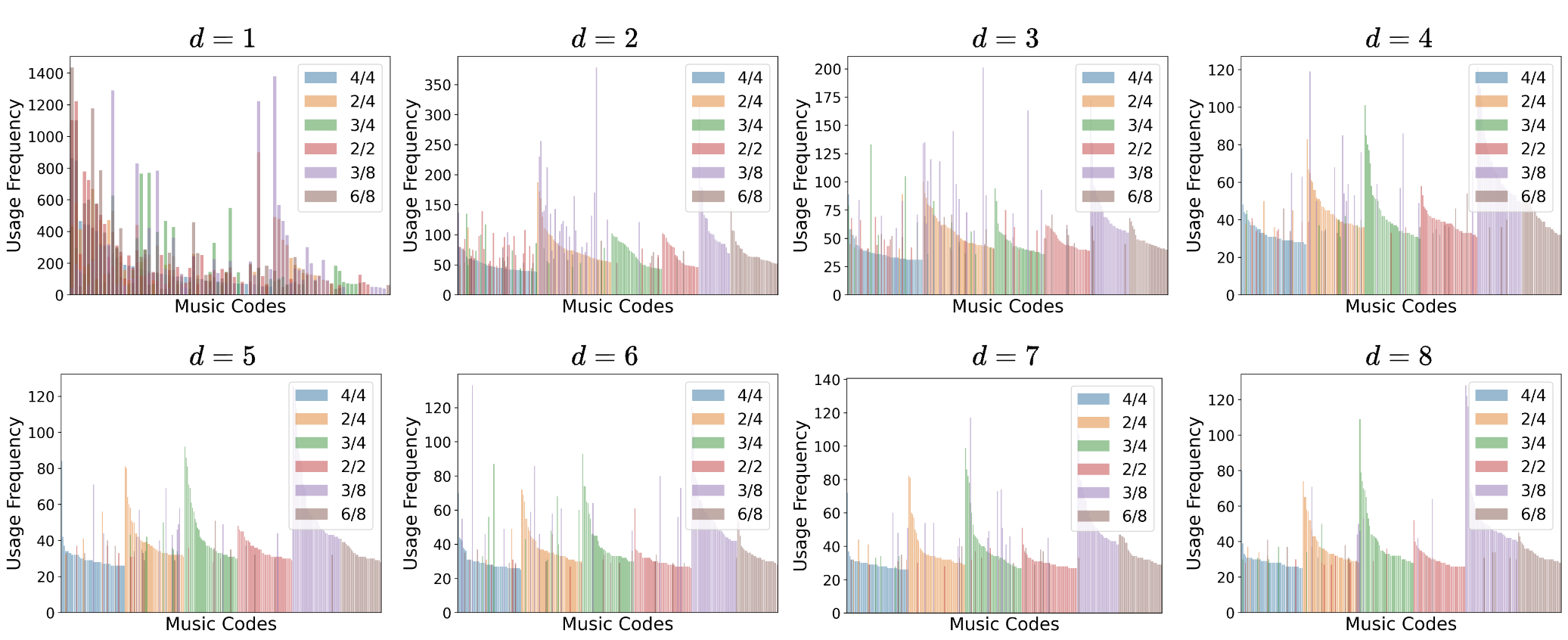
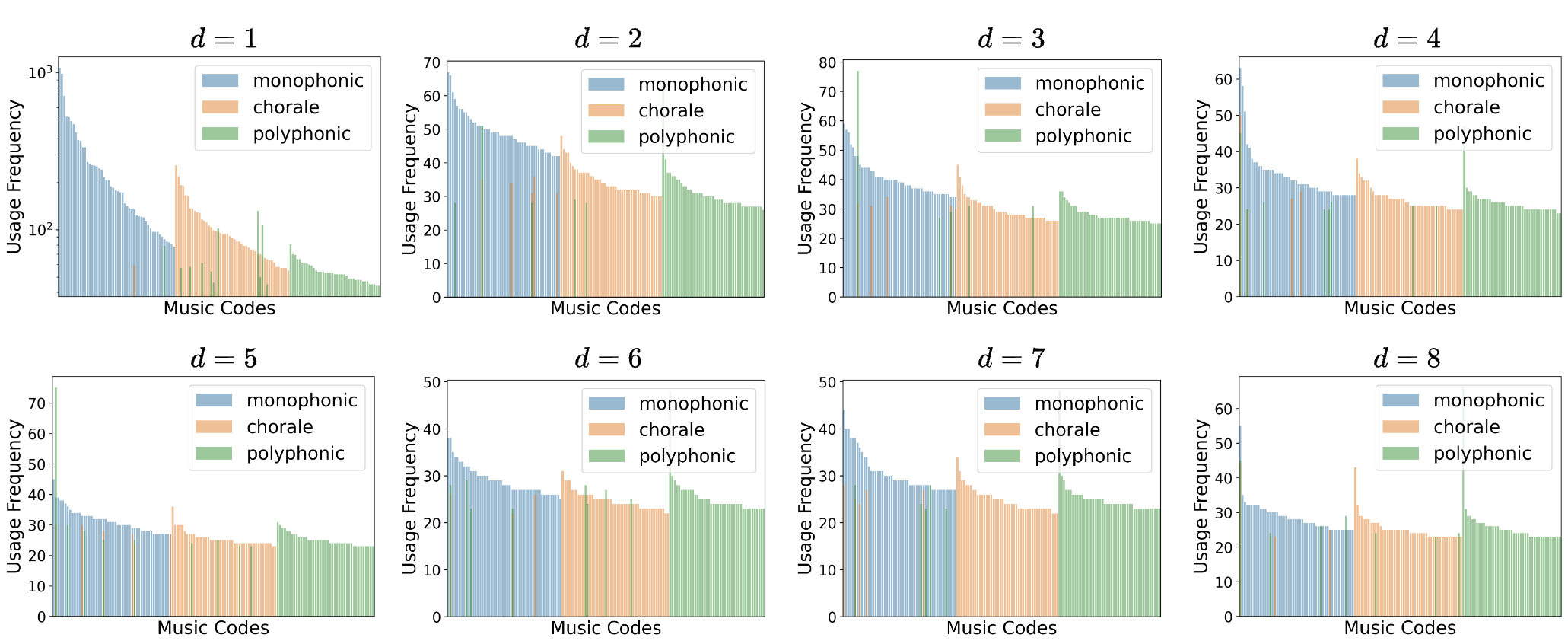
To further discover the music concepts learned through MuseTok, we examine the usage frequency of codes across different music textures and time signatures. Here we show the frequency of the 50 most used codes in each texture group or time signature group across all eight codebooks.
Music Textures
The top-50 frequently used codes in different texture groups are largely distinct at all codebooks.
Time Signatures
MuseTok almost omits the time signature difference in the first codebook, but gradually diverges in deeper codebooks.